Versioning - Python SDK
The definition code of a Temporal Workflow must be deterministic because Temporal uses event sourcing to reconstruct the Workflow state by replaying the saved history event data on the Workflow definition code. This means that any incompatible update to the Workflow Definition code could cause a non-deterministic issue if not handled correctly.
Introduction to Versioning
Because we design for potentially long running Workflows at scale, versioning with Temporal works differently. We explain more in this optional 30 minute introduction:
How to use the Python SDK Patching API
In principle, the Python SDK's patching mechanism operates similarly to other SDKs in a "feature-flag" fashion. However, the "versioning" API now uses the concept of "patching in" code.
To understand this, you can break it down into three steps, which reflect three stages of migration:
- Running
pre_patch_activitycode while concurrently patching inpost_patch_activity. - Running
post_patch_activitycode with deprecation markers formy-patchpatches. - Running only the
post_patch_activitycode.
Let's walk through this process in sequence.
Suppose you have an initial Workflow version called pre_patch_activity:
View the source code
in the context of the rest of the application code.
from datetime import timedelta
from temporalio import workflow
with workflow.unsafe.imports_passed_through():
from activities import pre_patch_activity
# ...
@workflow.defn
class MyWorkflow:
@workflow.run
async def run(self) -> None:
self._result = await workflow.execute_activity(
pre_patch_activity,
schedule_to_close_timeout=timedelta(minutes=5),
)
Now, you want to update your code to run post_patch_activity instead. This represents your desired end state.
View the source code
in the context of the rest of the application code.
from datetime import timedelta
from temporalio import workflow
with workflow.unsafe.imports_passed_through():
from activities import post_patch_activity
# ...
@workflow.defn
class MyWorkflow:
@workflow.run
async def run(self) -> None:
self._result = await workflow.execute_activity(
post_patch_activity,
schedule_to_close_timeout=timedelta(minutes=5),
)
Problem: You cannot deploy post_patch_activity directly until you're certain there are no more running Workflows created using the pre_patch_activity code, otherwise you are likely to cause a nondeterminism error.
Instead, you'll need to deploy post_patched_activity and use the patched function to determine which version of the code to execute.
Implementing patching involves three steps:
- Use patched to patch in new code and run it alongside the old code.
- Remove the old code and apply deprecate_patch.
- Once you're confident that all old Workflows have finished executing, remove
deprecate_patch.
Overview
We take a deep dive into the behavior of the patched() function in this optional 37 minute YouTube series:
Behavior When Not Replaying
If not replaying, and the execution hits a call to patched, it first checks the event history, and:
- If the patch ID is not in the event history, it will add a marker to the event history, upsert a search attribute, and return true. This happens in a given patch ID's first block.
- If the patch ID is in the event history, it won't modify the history, and it will return true. This happens in a given patch ID's subsequent blocks.
There is a caveat to the above, and we will discuss that below.
Behavior When Replaying With Marker Before-Or-At Current Location
If Replaying:
- If the code has a call to patched, and if the event history has a marker from a call to patched in the same place (which means it will match the original event history), then it writes a marker to the replay event history and returns true. This is similar to the behavior of the non-replay case, and just like in that case, this happens in a given patch ID's first block
- If the code has a call to patched, and the event history has a marker with that Patch ID earlier in the history, then it will simply return true and not modify the replay event history. This is similar to the behavior of the non-replay case, and just like in that case, this happens in a given patch ID's subsequent blocks
Behavior When Replaying With Marker After Current Location
If the Marker Event is after where the execution currently is in the event history, then, in other words, the patch is before the original patch, then the patch is too early. It will attempt to write the marker to the replay event history, but it will throw a non-deterministic exception because the replay and original event histories don't match
Behavior When Replaying With No Marker For that Patch ID
It will return false and not add anything to the event history. Furthermore, and this is the caveat mentioned in the preceeding section Behavior When Not Replaying, it will make all future calls to patched with that ID false -- even after it is done replaying and is running new code.
Why is this a caveat?
In the preceding section where we discussed the behavior when not replaying , we said that if not replaying, the patched function will always return true, and if the marker doesn't exist, it will add it, and if the marker already exists, it won't re-add it.
But what this is saying is that this doesn't hold if there was already a call to patched with that ID in the replay code, but not in the event history. In this situation, it won't return true.
A Summary of the Two Potentially Unexpected Behaviors
-
When Replaying, in the scenario of it hits a call to patched, but that patch ID isn't before/on that point in the event history, you may not expect that the event history after where you currently are matters. Because:
- If that patch ID exists later, you get an NDE (see above: Behavior When Replaying With Marker After Current Location).
- If it doesn't exist later, you don't get an NDE, and it returns false (see above: Behavior When Replaying With No Marker For that Patch ID).
-
When Replaying, if you hit a call to patched with an ID that doesn't exist in the history, then not only will it return false in that occurence, but it will also return false if the execution surpasses the Replay threshold and is running new code. (see above: Behavior When Replaying With No Marker For that Patch ID).
Implications of the Behaviors
If you deploy new code while a worker is down, any workflows that were in the middle of executing will replay using old code and then for the rest of the execution, they will either:
- Use new code if there was no call to patched in the replay code
- If there was a call to patched in the replay code, they will run the non-patched code during and after replay
This might sound odd, but it's actually exactly what's needed because that means that if the future patched code depends on earlier patched code, then it won't use the new code -- it will use the old code. But if there's new code in the future, and there was no code earlier in the body that required the new patch, then it can switch over to the new code, and it will do that.
Note that this behavior means that the Workflow does not always run the newest code. It only does that if not replaying or if surpassed replay and there hasn't been a call to patched (with that ID) throughout the replay.
Recommendations
Based on this behavior and the implications, when patching in new code, always put the newest code at the top of an if-patched-block.
if patched('v3'):
# This is the newest version of the code.
# put this at the top, so when it is running
# a fresh execution and not replaying,
# this patched statement will return true
# and it will run the new code.
pass
elif patched('v2'):
pass
else:
pass
The following sample shows how patched() will behave in a conditional block that's arranged differently.
In this case, the code's conditional block doesn't have the newest code at the top.
Because patched() will return True when not Replaying (except with the preceding caveats), this snippet will run the v2 branch instead of v3 in new executions.
if patched('v2'):
# This is bad because when doing a new execution (i.e. not replaying),
# patched statements evaluate to True (and put a marker
# in the event history), which means that new executions
# will use v2, and miss v3 below
pass
elif patched('v3'):
pass
else:
pass
Patching in new code
Using patched() inserts a marker into the Workflow History.
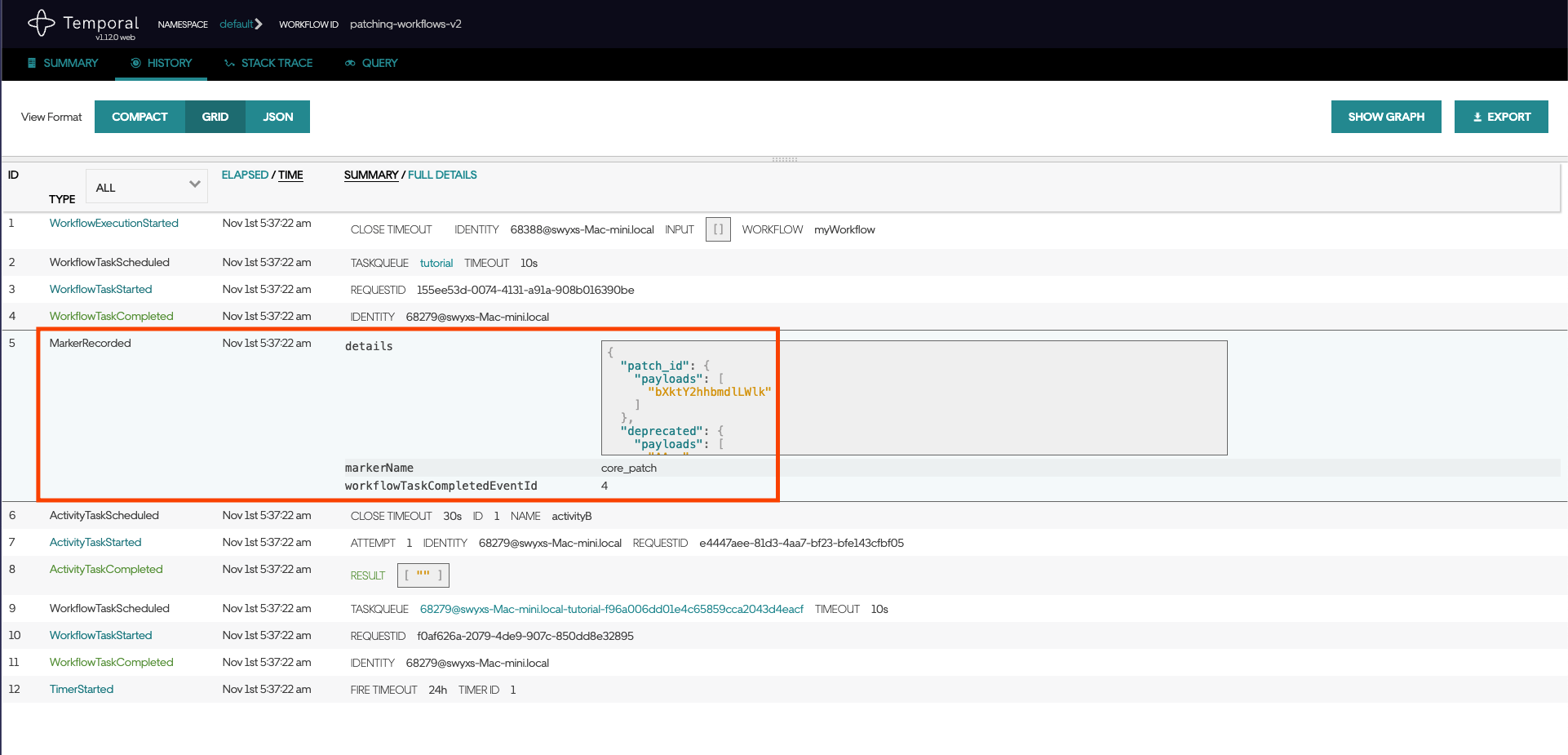
During replay, if a Worker encounters a history with that marker, it will fail the Workflow task when the Workflow code doesn't produce the same patch marker (in this case, my-patch). This ensures you can safely deploy code from post_patch_activity as a "feature flag" alongside the original version (pre_patch_activity).
View the source code
in the context of the rest of the application code.
# ...
@workflow.defn
class MyWorkflow:
@workflow.run
async def run(self) -> None:
if workflow.patched("my-patch"):
self._result = await workflow.execute_activity(
post_patch_activity,
schedule_to_close_timeout=timedelta(minutes=5),
)
else:
self._result = await workflow.execute_activity(
pre_patch_activity,
schedule_to_close_timeout=timedelta(minutes=5),
)
Understanding deprecated Patches in the Python SDK
After ensuring that all Workflows started with pre_patch_activity code have finished, you can deprecate the patch.
Once you're confident that your Workflows are no longer running the pre-patch code paths, you can deploy your code with deprecate_patch().
These Workers will be running the most up-to-date version of the Workflow code, which no longer requires the patch.
The deprecate_patch() function works similarly to the patched() function by recording a marker in the Workflow history.
This marker does not fail replay when Workflow code does not emit it.
Deprecated patches serve as a bridge between the pre-patch code paths and the post-patch code paths, and are useful for avoiding errors resulting from patched code paths in your Workflow history.
View the source code
in the context of the rest of the application code.
# ...
@workflow.defn
class MyWorkflow:
@workflow.run
async def run(self) -> None:
workflow.deprecate_patch("my-patch")
self._result = await workflow.execute_activity(
post_patch_activity,
schedule_to_close_timeout=timedelta(minutes=5),
)
Safe Deployment of post_patch_activity
Once you're sure that you will no longer need to Query or Replay any of your pre-patch Workflows, you can then safely deploy Workers that no longer use either the patched() or deprecate_patch() calls:
View the source code
in the context of the rest of the application code.
# ...
@workflow.defn
class MyWorkflow:
@workflow.run
async def run(self) -> None:
self._result = await workflow.execute_activity(
post_patch_activity,
schedule_to_close_timeout=timedelta(minutes=5),
)
Best Practice of Using Python Dataclasses as Arguments and Returns
As a side note on the Patching API, its behavior is why Temporal recommends using single dataclasses as arguments and returns from Signals, Queries, Updates, and Activities, rather than using multiple arguments.
The Patching API's main use case is to support branching in an if block of a method body.
It is not designed to be used to set different methods or method signatures for different Workflow Versions.
Because of this, Temporal recommends that each Signal, Activity, etc, accepts a single dataclass and returns a single dataclass, so the method signature can stay constant, and you can do your versioning logic using patched() within the method body.
How to use Worker Versioning in Python
Worker Versioning is currently in Pre-release.
See the Pre-release README for more information.
A Build ID corresponds to a deployment. If you don't already have one, we recommend a hash of the code--such as a Git SHA--combined with a human-readable timestamp. To use Worker Versioning, you need to pass a Build ID to your Java Worker and opt in to Worker Versioning.
Assign a Build ID to your Worker and opt in to Worker Versioning
You should understand assignment rules before completing this step. See the Worker Versioning Pre-release README for more information.
To enable Worker Versioning for your Worker, assign the Build ID--perhaps from an environment variable--and turn it on.
# ...
worker = Worker(
task_queue="your_task_queue_name",
build_id=build_id,
use_worker_versioning=True,
# ... register workflows & activities, etc
)
# ...
Importantly, when you start this Worker, it won't receive any tasks until you set up assignment rules.
Specify versions for Activities, Child Workflows, and Continue-as-New Workflows
Python support for this feature is under construction!
By default, Activities, Child Workflows, and Continue-as-New Workflows are run on the build of the workflow that created them if they are also configured to run on the same Task Queue. When configured to run on a separate Task Queue, they will default to using the current assignment rules.
If you want to override this behavior, you can specify your intent via the versioning_intent argument available on the methods you use to invoke these commands.
For example, if you want an Activity to use the latest assignment rules rather than inheriting from its parent:
# ...
await workflow.execute_activity(
say_hello,
"hi",
versioning_intent=VersioningIntent.USE_ASSIGNMENT_RULES,
start_to_close_timeout=timedelta(seconds=5),
)
# ...
Tell the Task Queue about your Worker's Build ID (Deprecated)
This section is for a previous Worker Versioning API that is deprecated and will go away at some point. Please redirect your attention to Worker Versioning.
Now you can use the SDK (or the Temporal CLI) to tell the Task Queue about your Worker's Build ID. You might want to do this as part of your CI deployment process.
# ...
await client.update_worker_build_id_compatibility(
"your_task_queue_name", BuildIdOpAddNewDefault("deadbeef")
)
This code adds the deadbeef Build ID to the Task Queue as the sole version in a new version set, which becomes the default for the queue.
New Workflows execute on Workers with this Build ID, and existing ones will continue to process by appropriately compatible Workers.
If, instead, you want to add the Build ID to an existing compatible set, you can do this:
# ...
await client.update_worker_build_id_compatibility(
"your_task_queue_name", BuildIdOpAddNewCompatible("deadbeef", "some-existing-build-id")
)
This code adds deadbeef to the existing compatible set containing some-existing-build-id and marks it as the new default Build ID for that set.
You can also promote an existing Build ID in a set to be the default for that set:
# ...
await client.update_worker_build_id_compatibility(
"your_task_queue_name", BuildIdOpPromoteBuildIdWithinSet("deadbeef")
)
You can also promote an entire set to become the default set for the queue. New Workflows will start using that set's default build.
# ...
await client.update_worker_build_id_compatibility(
"your_task_queue_name", BuildIdOpPromoteSetByBuildId("deadbeef")
)